
我们知道多线程能高并发的解决众多每日任务,合理地提升繁杂应用软件的性能,在现实研发中充当着十分关键的人物角色
可是应用多线程也提供了许多风险性,而且由线程造成的问题通常在测验中无法发觉,到了网上就会导致重要的问题和损害
下边我能融合好多个具体实例,协助我们在工作中做避开这种问题
多线程问题
最先详细介绍下采用的多线程会有什么问题
应用多线程的问题较大水平上来源于好几个线程对同一自变量的实际操作权,及其不一样线程中间实行次序的可变性
《Java并发编程实战》这本书中提及了三种多线程的问题:安全系数问题、活动性问题和性能问题
安全系数问题
例如有一段非常简单的扣库存量作用实际操作,如下所示:
在单线程自然环境下,这一方式能恰当工作中,但在多线程自然环境下,就会造成失误的結果
--count看起来是一个实际操作,但其实它包括三步(载入-改动-载入):
- 读取count的值
- 将值减一
- 最终把数值取值给count
如下图展现了一种不正确的实施全过程,当有两个线程1、2与此同时实行该方式时,他们载入到count的值全是10,最终回到結果全是9;代表着很有可能有两人选购了产品,但库存量却只减了1,这针对真正的生产过程是无法进行的
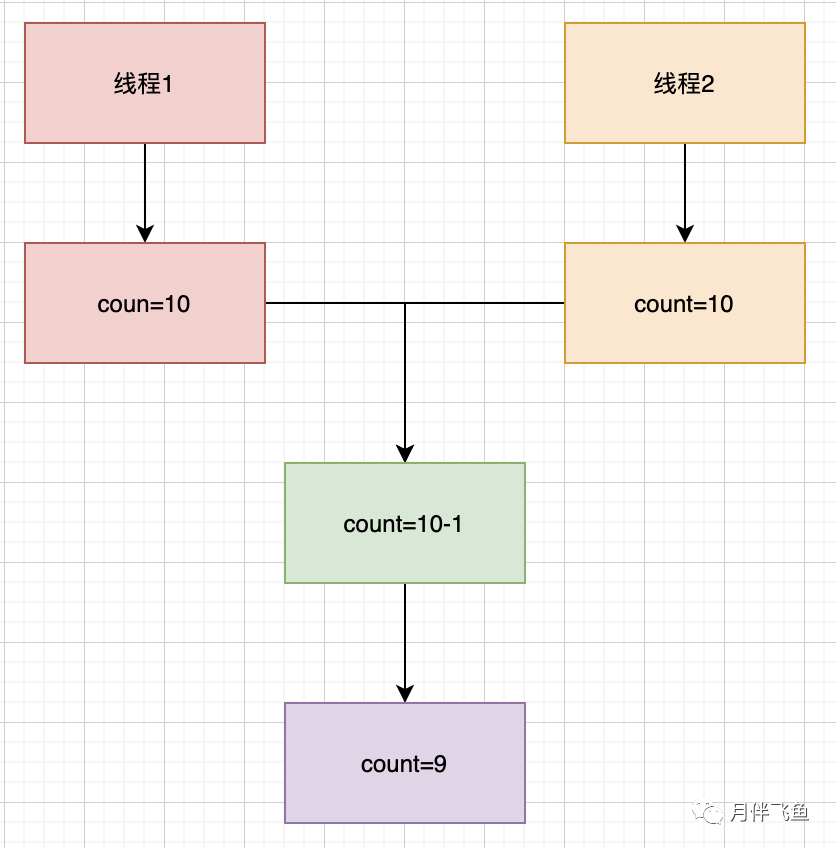
像上边事例那样因为不适当的实行时钟频率造成有误結果的状况,是一种很普遍的高并发安全隐患,被称作竞态标准
decrement()方式这一造成产生竞态标准的编码区被称作临界区
防止这些问题,必须确保载入-改动-载入那样复合型实际操作的原子性
在Java中,有很多方法可以完成,例如应用synchronize内嵌锁或ReentrantLock显式锁的加锁体制、应用线程安全性的分子类、及其选用CAS的方法等
活动性问题
活跃性问题指的是,某一实际操作由于堵塞或循环系统,没法执行下来
最经典的有三种,各自为死锁、活锁和挨饿
死锁
最多见的活动性问题是死锁
死锁就是指好几个线程中间互相等候获得另一方的锁,又不容易放空自己占据的锁,而造成堵塞促使这种线程没法运作下来便是死锁,它通常是不规范的应用加锁体制及其线程间实行次序的不能意料性引发的
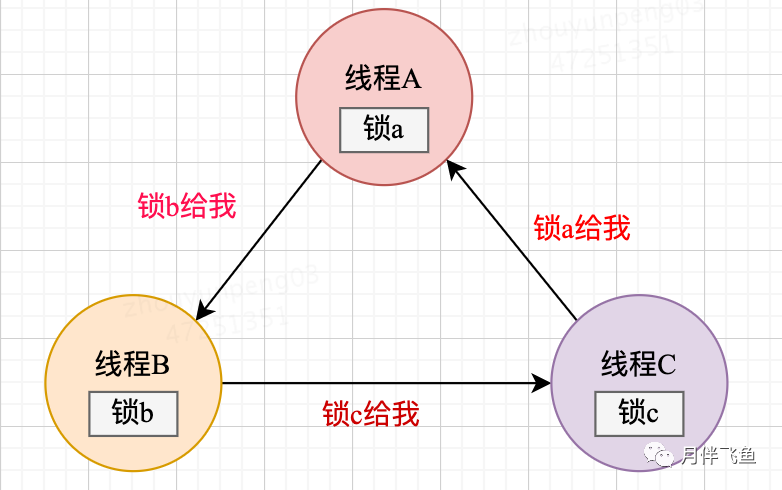
如何预防死锁
1.尽可能确保加锁次序是一样的
例如有A,B,C三把锁。
- Thread 1的加锁顺序为A、B、C那样的。
- Thread 2的加锁次序为A、C,那样就不容易死锁。
假如Thread2的加锁次序为B、A或是C、A那样次序也不一致了,就会发生死锁问题。
2.尽可能用请求超时舍弃体制
Lock插口给予了tryLock(long time, TimeUnit unit)方式,该方式 可以根据固定不动时间等候锁,因而线程可以在获得锁请求超时之后,积极释放出来以前早已得到的任何的锁。可以防止死锁问题
活锁
活锁与死锁十分类似,也是程序流程一直等不到結果,但比照于死锁,活锁是活的,是什么意思呢?由于已经运作的线程并沒有堵塞,它自始至终在运转中,却一直无法得到結果
挨饿
饥饿就是指线程必须一些資源时自始至终无法得到,尤其是CPU 資源,就会造成线程一直不可以运作而发生的问题。
在 Java 中有线程优先的定义,Java 中优先分成 1 到 10,1 最少,10 最大。
如果我们把某一线程的优先设定为 1,这也是最少的优先,在这样的情况下,这一线程就会有很有可能自始至终分派不上 CPU 資源,而致使长期没法运作。
性能问题
线程自身的建立、及其线程中间的转换都需要耗费資源,假如经常的建立线程或是CPU在线程生产调度耗费的時间远高于线程运作的時间,应用线程反倒因小失大,乃至导致CPU负荷过高或是OOM的不良影响
举例子
线程不安全类
实例1
应用线程不安全结合(ArrayList、HashMap等)要实现同歩,最好是应用线程安全性的高并发结合
在多线程自然环境下,对线程不安全的结合解析xml开展使用时,很有可能会抛出去ConcurrentModificationException的出现异常,也就是常说的fail-fast体制
下边事例仿真模拟了好几个线程与此同时对ArrayList实际操作,线程t1遍历list并打印,线程t2向list加上原素

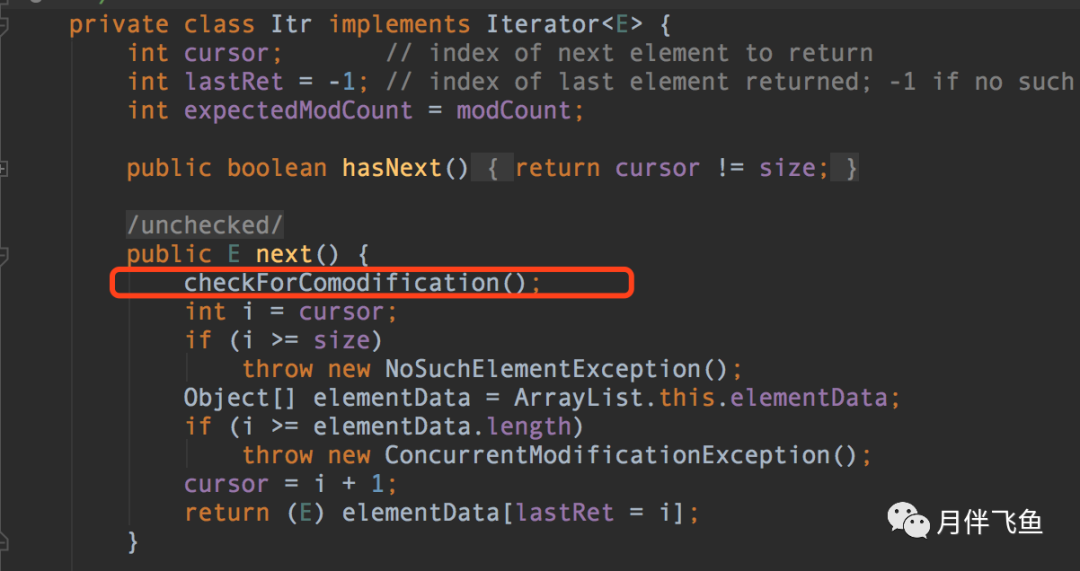
进入抛出现异常的ArrayList源代码中,能够看见解析xmlArrayList是根据内部结构完成的迭代器进行的
启用迭代器的next()方式获得下一个原素时,会先根据checkForComodification()方式查验modCount和expectedModCount是不是相同,若不相等则抛出去ConcurrentModificationException

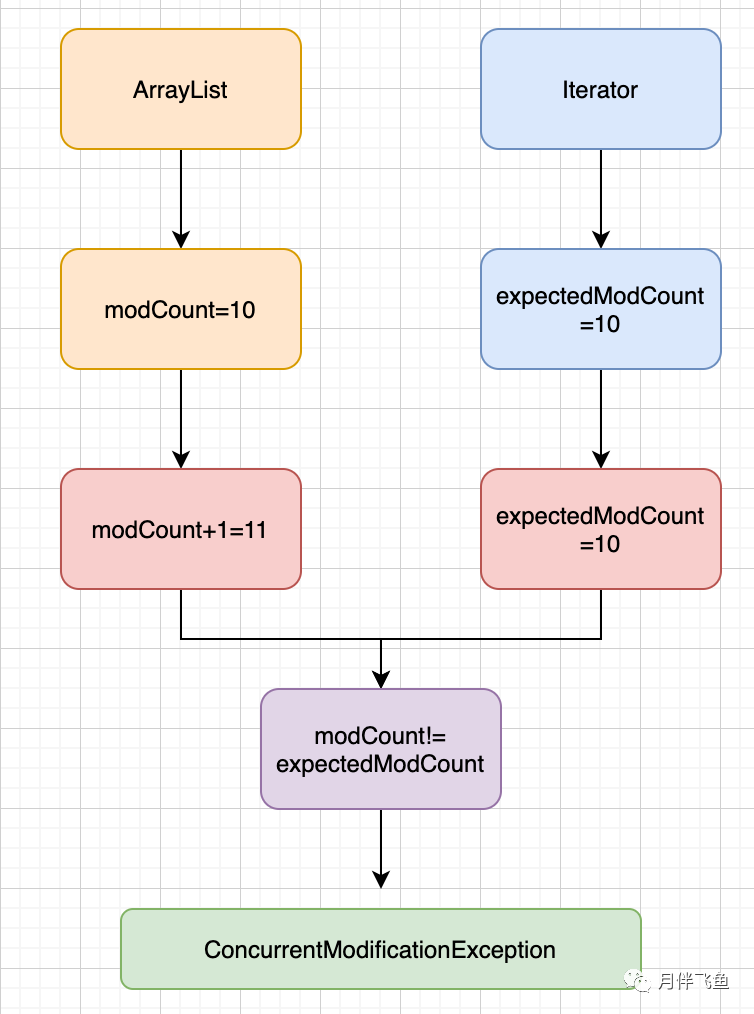
modCount是ArrayList的特性,表明结合构造被改动的频次(目录长短产生变化的频次),每一次启用add或remove等方式都是会使modCount加1
expectedModCount是迭代器的特性,在迭代器案例建立时被赋与和解析xml前modCount相同的值(expectedModCount=modCount)
因此当有别的线程加上或删掉结合原素时,modCount会提升,随后结合遍历经expectedModCount不等于modCount,就会抛出异常
应用加锁机制操作线程不安全的集合类
如上边编码,用synchronized关键词锁定对list的操作,就不容易抛出异常。但是用synchronized等同于把锁定的代码块串行化,特性上不是占上风的
强烈推荐应用线程安全性的高并发java工具
JDK1.5添加了许多线程安全性的java工具供应用,如CopyOnWriteArrayList、ConcurrentHashMap等高并发器皿
日常开发设计中强烈推荐应用这种java工具来完成多线程程序编写
实例2
不必将SimpleDateFormat做为局部变量应用
SimpleDateFormat事实上是一个线程不安全的类,其直接原因是SimpleDateFormat的里面完成对一些共享资源自变量的操作沒有开展同歩

提议将SimpleDateFormat做为静态变量应用,或是相互配合ThreadLocal应用
非常简单的作法是将SimpleDateFormat做为静态变量应用就可以
但如果是在for循环中应用,会建立许多案例,可以提升下相互配合ThreadLocal应用
强烈推荐应用Java8的LocalDateTime和DateTimeFormatter
LocalDateTime和DateTimeFormatter是Java 8引进的新特点,他们不仅仅是线程安全性的,并且应用更便捷
强烈推荐在现实开发设计选用LocalDateTime和DateTimeFormatter取代Calendar和SimpleDateFormat
锁的恰当释放出来
假定有那样一段伪代码:
这一段编码中在finally代码块释放出来锁以前,实行了一段领域模型
倘若造化弄人这一段逻辑性中依靠服务项目不能用造成占有锁的进程不可以取得成功释放出来锁,会产生别的进程因不能获得锁而堵塞,最后线程池挨打满的问题
因此在释放出来锁以前;finally子句中应当仅有对现阶段进程占据的資源(如锁、IO流等)开展释放出来的一些解决
也有便是获得锁时设定有效的中断時间
为了防止进程因获得不上锁而一直堵塞,可以设定一个请求超时時间,当获得锁请求超时后,进程可以抛出异常或回到一个失误的状态码。在其中请求超时時间的设定也需要有效,不可太长,而且应当超过锁定的领域模型的实施時间。
恰当应用线程池
实例1
不必将线程池做为静态变量应用
在for循环中建立线程池,那麼每一次实行该方式时,入参的list长短有多大便会建立多少个线程池,而且方式实行完后没有立即启用shutdown()方式将线程池消毁
那样的话,伴随着持续有要求进去,线程池占有的运行内存会愈来愈多,便会造成经常fullGC乃至OOM。每一次方式启用都建立线程池是很不科学的,由于这和自身经常建立、消毁进程沒有差别,不但沒有运用线程池的优点,反倒还会继续消耗线程池需要的大量資源
因此尽可能将线程池做为局部变量应用
实例2
慎重应用默认设置的线程池静态方法
以上三个默认设置线程池的安全风险:
newFixedThreadPool建立的线程池corePoolSize和maximumPoolSize值是相同的,应用的阻塞队列是LinkedBlockingQueue。
newSingleThreadExecutor将corePoolSize和maximumPoolSize都设定为1,也应用的LinkedBlockingQueue
LinkedBlockingQueue默认设置容积为Integer.MAX_VALUE=2147483647,针对真真正正的设备而言,可以被觉得是无边序列
- newFixedThreadPool和newSingleThreadExecutor在运转的连接数超出corePoolSize时,之后的要求会都被放进阻塞队列中等候,由于阻塞队列设定的过大,之后要求不可以迅速不成功而长期堵塞,就有可能导致要求端线程池挨打满,压垮全部服务项目。
newCachedThreadPool将corePoolSize设定为0,将maximumPoolSize设置为Integer.MAX_VALUE,阻塞队列应用的SynchronousQueue,SynchronousQueue不容易储存等候实行的每日任务
- 因此newCachedThreadPool是来啦每日任务就建立进程运作,而maximumPoolSize等同于无尽的设定,促使建立的连接数很有可能会将设备运行内存布满。
因此必须依据本身工作和系统配置建立自定线程池
连接数提议
线程池corePoolSize总数设定提议:
1.CPU密集式运用
CPU密集的意思是每日任务必须完成很多繁杂的计算,几乎沒有堵塞,必须CPU长期高速运转。
一般公式计算:corePoolSize=CPU核数 1个进程。JVM可运作的CPU核数可以根据Runtime.getRuntime().availableProcessors()查询。
2.IO密集式运用
IO密集式每日任务会涉及许多的硬盘读写能力或数据传输,进程耗费大量的时间段在IO堵塞上,而不是CPU计算。一般的业务流程运用都归属于IO密集式。
参照公式计算:最好连接数=CPU数/(1-堵塞指数); 堵塞指数=进程等待的时间/(进程等待的时间 CPU解决時间) 。
IO密集式每日任务的CPU解决時间通常远低于进程等待的时间,因此堵塞指数一般觉得在0.8-0.9中间,以4核双槽CPU为例子,corePoolSize可设定为 4/(1-0.9)=40。自然主要的设定或是要依据设备具体运转中的各种指标值而定。
文中摘自微信公众平台「月伴飞鱼」,创作者日常加气站。转截文中请联络月伴飞鱼微信公众号。
